
Recently, Atlassian opened up their new Bitbucket Pipelines feature to users. If you're not familiar, Pipelines is Atlassian's solution to allow continuous integration (CI) to happen from directly within a repository. Even though it's still in beta, we tried to imagine how this feature could function as part of our team's routine.
To be fair, we really shouldn't compare Pipelines to more established commercial and open-source CI solutions just yet - but I'm going to anyway. Atlassian's decision to release this feature now is most likely their response to growing market interest. In fact, I'd wager that they likely held back on feature sets to better focus their beta's goals.
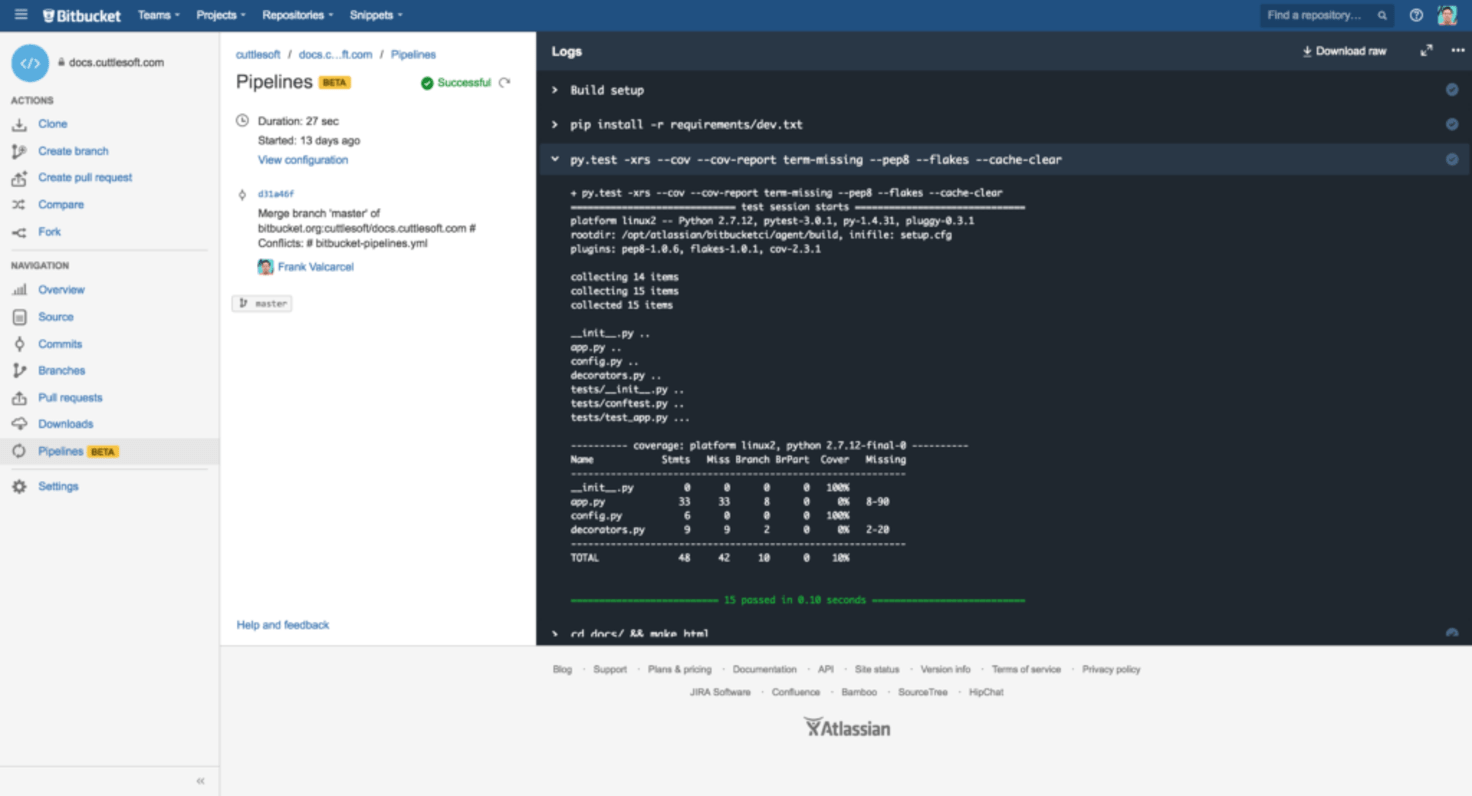
Pipelines - What it is / What it isn't
Pipelines is going to let developers manage infrastructure and delivery under one integrated, familiar roof -- eventually. The beta already has me getting used to the idea that every repo can have integration tests, just so long as I include a simple bitbucket-pipelines.yml file (sound familiar?).
Pipelines isn't going to replace services like TravisCI or CircleCI, nor will it be a suitable replacement for self-managed options like Jenkins. Instead, Pipelines is going to bring an easy way to add CI to any code repository, but it's going to take a long time before we see it begin to take over for existent and complete integration/delivery solutions. To explain, let me share what we learned when we tried to implement a complete delivery solution using Pipelines on one of our internal projects.
The Good Parts
Off the bat, I love that I can import any existing (public?) Docker image, and to its benefit, the bitbucket-pipelines.yml file resembles docker-compose a lot more than it does a .travis.yml. This makes the way environments are constructed seem more familiar and contains fewer surprises. At Cuttlesoft, our CI builds rely heavily on docker-compose. That experience has really helped us optimize this component of our own internal delivery pipelines.
Secondly, there's the step and branch keys. Defining build steps incrementally, in code - this was really interesting to me. I think that most of us would agree that that's how we think about them in our head. Builds are synchronous, so why shouldn't their configuration be also? The branch key makes Pipelines feel like it’s repository first (I'll come back to this). This has existed in other integration services for some time, but in self-managed CI platforms it can be rather laborious to orchestrate simple branch-based rules. This is actually one of the original reasons that motivated us to build argo. Pipelines' branch supports regex patterns as well, so if you want to issue new builds whenever anyone pushes/merges into a feature branch, try feature/* and you're off.
I'm also a fan of how environment variables are managed. I think the product team put a lot of thought into this. Environment variables are managed at the repo and account levels and follow the account's permissions. You can even secure a variable so that its value is hidden in build logs - a feature I hope makes its way around!
The Bad
Atlassian already lists the current limitations in their docs, so I'm not going to mention build time/size restrictions, but I will say that their original decision to only support Git was confusing.
When you begin your first Pipelines adventure, you're going to be tempted to create/edit your bitbucket-pipelines.yml file in the web-based editor. Resist that urge. This is one user experience that I think can get Bitbucket Pipelines into trouble. Though there's not a huge difference between this and say, editing the file, committing, and then re-pushing -- the experience is hurt by the lack of even simple YAML linting. So, when you're editing the file 8 times just to get it to run, and using the web-based commit interface, and waiting... it's going to feel really really daunting.

Thanks to Gary Kramlich you can run a pipeline locally using his local-pipelines tool!
Integrations are another pain point. Though I certainly expect that the Pipelines team is actively working on bringing more and more to the product, I bet this implementation won't change much beyond the beta. That's an issue for me because it means more code to manage. For example, consider that all the currently available integrations direct you to fork a separate repository. This means you’re including more code in your repo specifically for deployment steps. Code you now have the responsibility of maintaining.
If you're pushing code to Amazon EC2 Container Service (or "ECS", a current Pipelines integration) from Jenkins, there's a plugin for you. That plugin uses authentication that's already part of the platform. And yes, it basically just runs the bash command for you... but I happily allow it to, because it means I'm not responsible for it. Realize that if a change is made to the way this plugin interfaces with ECS, an update fixes it for ALL of my builds. If you need to make changes to this for one repo, you have to make it for all that use this file. This could take up valuable developer time.
This method of tying in other integrations is unintuitive and probably requires a lot of trial and error when troubleshooting builds. I know it did for me.
Another caveat is the default environment they provide. Bitbucket Pipelines' default environment is a great base and looks like it's just an extended Ubuntu image that the product team pre-installs some common CI tools to. The limitation here is that if you're not going to use the default environment, you're going to have to get creative.
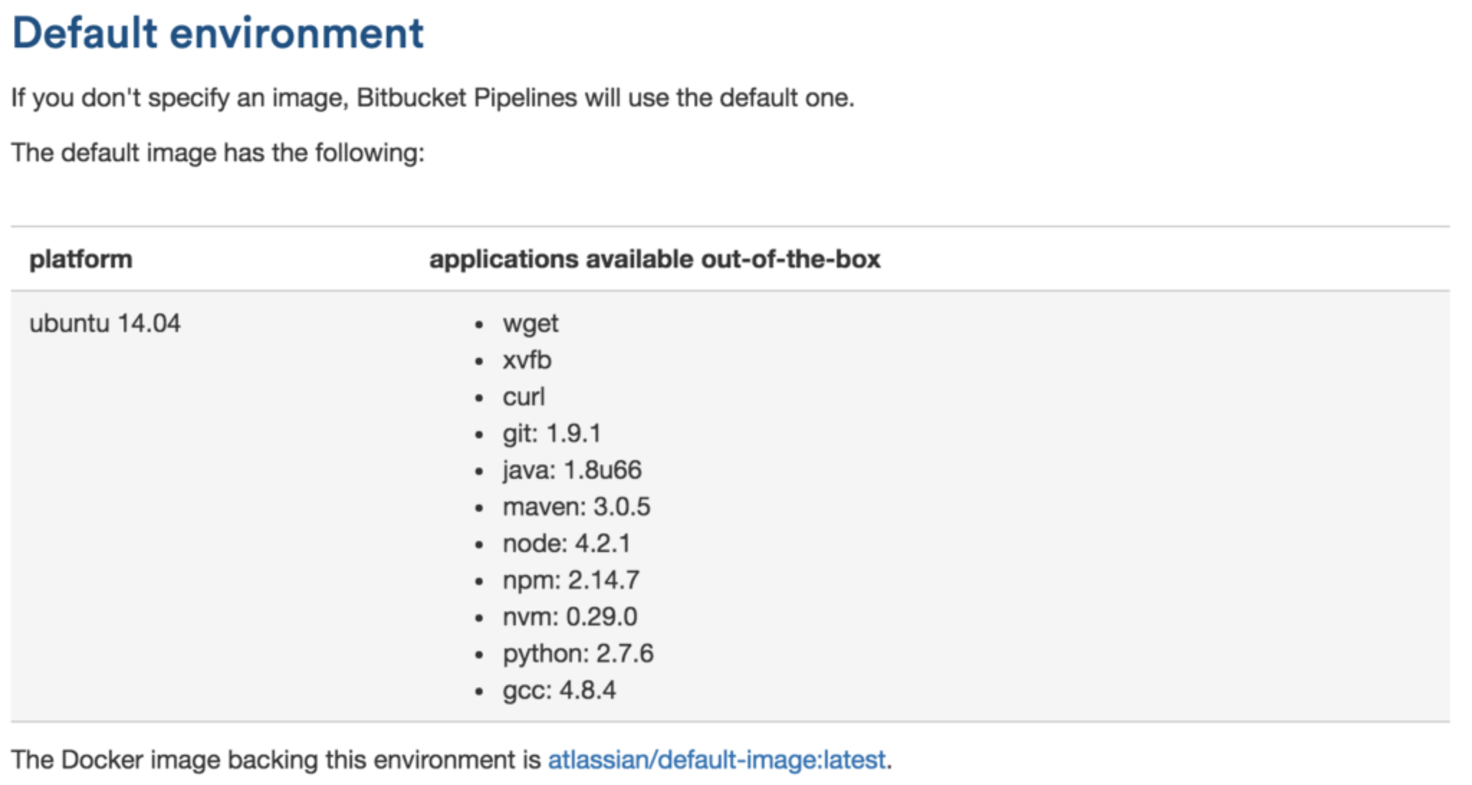
Remember when I said that the bitbucket-pipelines.yml reminded me more of docker-compose? Well, that didn't last long. I think this feature would kick ass if I could pull multiple images and build links between containers. At least then my dependency issue wouldn’t require running a lot of apt-get installs to create my environment.
Finally, and this is probably me being nit-picky, but the "Build Setup" output is kind of noisy, and, honestly, I feel like I should have a way to silence it.
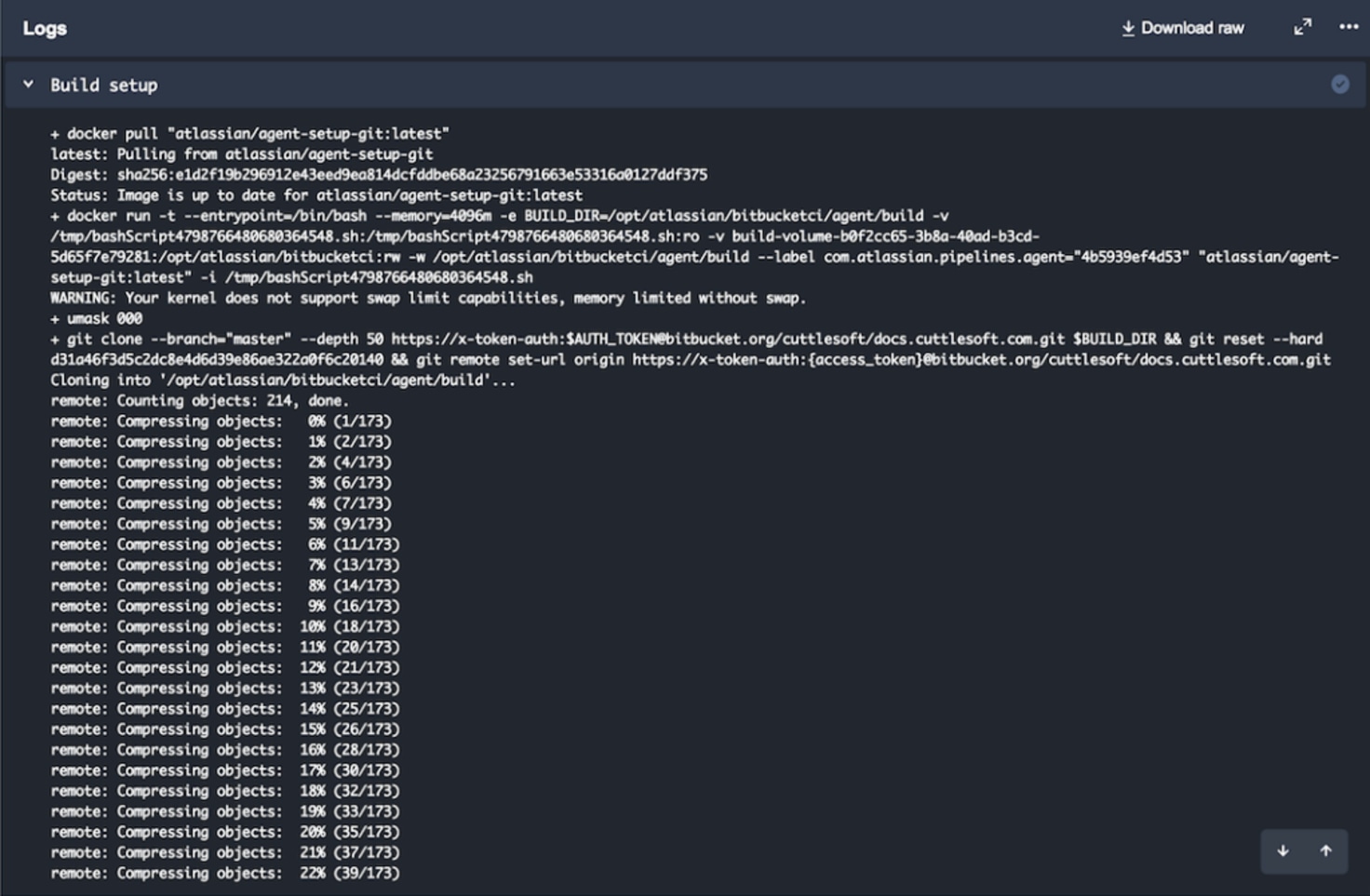
Repository First
The implications of a CI tool that's tightly coupled to your code repo are hard to determine right away, and, really, I can't make assumptions as to how anyone else would implement this. However, the concept of the repository being the first link in your integration and delivery supply chain is very interesting. There will likely be some critics that say it always is, but I am going to disagree with that. As I mentioned, integrations come from forking or adding new code that does the work of moving your build along to another service or environment. The repository here is now both the vessel and the navigational system. And you're probably asking... "What's the difference?"
The difference is this: events on the repository trigger builds, but in every other service, code has to be checked out first to then run through the build steps. In the Pipelines' scenario, code is already present; there's no delta to clone. Builds now execute in succession to a developer pushing the new delta up on a branch that triggers the Pipelines' build. We're used to systems where the build steps and environment construction don't require new commits, so unless Atlassian adds a "Build Now" button to the feature (which isn't going to fit in this workflow), take note that every build will require interaction with the repository.
Verdict
I really like that Atlassian is taking this direction with Bitbucket Pipelines. It means that the idea of CI/CD is now so mainstream that even the big guys are noting the value it could bring to their existing product lines. Also, it shows me that Atlassian really knows their customers. Imagine a feature like this in GitHub - it would really upset that user base. GitHub has always been the more popular collaborative ecosystem, and as a result, that's created a solid market for third-party services like Travis and CircleCI. A GitHub “OEM” integration solution would threaten that, and I strongly believe that would upset GitHub's user base.
Bitbucket’s model is very different than that of GitHub. To the Bitbucket user, this offering will encourage them to (eventually) bring more of their infrastructure onto the Atlassian cloud. And even though I wonder how this will fit alongside Bamboo for Atlassian enterprise users, I believe the two use cases still differ.
If you're looking to try Pipelines it's really easy to get started by just signing up for the beta. The documentation is really helpful (not common for new features of this scale) and can help you get rolling.
The product is free during the beta with build limitations being the only imposed restriction. That said, expect Pipelines to have a freemium model, with the price tied to build times and sizes of private repositories.
...
If you’re adapting your deployment strategies and want to modernize your cloud-based applications and delivery methods, consider consulting with Cuttlesoft.

